(This is a draft and truncated version - for final and full version, see
Concise Encyclopedia of Biostatistics for Medical Professionals)
validity, see also validity (types of)
Validity of a tool is its ability to assess correctly or its appropriateness for use in a particular setup. In medicine, the term is used for devices, factors, data, design, estimate, evidence, tests, results, scoring systems, studies, and a host of other tools. Do not confuse this with accuracy, Accuracy is generally for a single measurement whereas validity is the ability to hit the target on average.
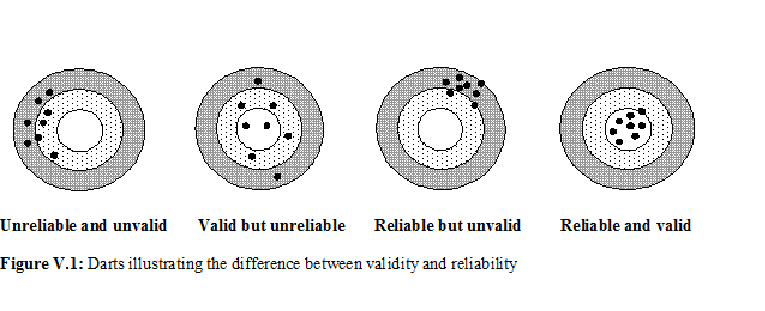
There is some confusion in the literature about the terms validity and reliability. The difference between the two is aptly illustrated in Figure V.1. Reliability is hitting the same point in repeated attempts although this may be far away from the target (see third panel). Validity is hitting around the target (second panel). If hits are close together and near the target every time, both reliability and validity are high (fourth panel). Lack of validity can be due to systematic bias or for any other reason. See bias in medical studies and their minimization for further details of the types of bias that can affect validity. If the bias is small, we say that the tool has high validity and if the bias is large we say that the validity is low.
What signs and symptoms or hematological parameters (such as hematocrit) can correctly identify cases of dengue fever in early stages because serological evidence takes time? Is BP > 140/90 mmHg the right definition for hypertension or is BP > 160/95 more correct? Both the definitions are used. (See [1, 2], these incidentally are nearly consecutive articles in the same journal but with varying definitions.) This means that those with BP = 150/92 are considered hypertensive by one definition but not by the other. How can one distinguish, without error, a hypothyroid condition from euthyroid goiter? How can one correctly ascertain cause of death in an inaccessible rural area where a medical doctor is not available? How can age be correctly assessed when a dependable record is not available? Can the diet content of an individual be adequately assessed by taking a three-day history? How can physical activity be validly measured? Many other examples can be cited where validity is an important concern.
Validity is context-specific, for example, high validity of a tool in hospital-A does not necessarily mean that this will be so in hospital-B as well. A highly valid tool in better nourished children may not work well in under-nourished children. It intimately depends on the case mix. Thus validity is qualified for the type of subjects it is evaluated.
Validity of Diagnostic Tests
In practice, no medical test is 100% perfect. A computed tomography (CT) scan can give a false-negative or false-positive result, and a negative histologic result for a specimen is no guarantee that proliferation is absent although in this case positive predictivity is nearly 100%. The values of measurements such as creatinine level, platelet count, and total lung capacity are indicative of different medical conditions rather than absolute, i.e., they mostly estimate the likelihood of a disease. Signs and symptoms seldom provide infallible evidence, and have to be supplemented with other clinical information for coming to any conclusion worth implementing.
Because all these tools are imperfect, decisions based on them are also necessarily probabilistic rather than definitive. Their validity in a particular setup is generally measured in terms of indices such as sensitivity and specificity and positive and negative predictivities (see these topics for details). These terms are applied not just to the conventional laboratory and radiological tests but also to the other clinical evaluation tools such as signs and symptoms, and attitudes and behavior. These indices measure the validity of these tools on 0–1 scale with 0 saying not helpful at all and 1 saying they are perfect in reaching to a right conclusion. The details under those topics will tell you that sometimes highly sensitive and sometimes highly specific test is more valid for a particular application. Also, that sensitivity-specificity are evaluated on subjects who are already known to have or not have the disease or the condition, whereas predictivities provide valid measurement of the diagnostic utility of the tools in local context. You may also like to review the topic receiver operating characteristic (ROC) curves that provide information on overall performance of quantitative tests on the basis of sensitivity-specificity of the quantitative tests at different cutoffs.
Validity of Medical Information
Besides diagnostic tools, other ‘tools’ used in health and medicine include information on a patient or a person obtained in a variety of ways – previous records, interview, examination, and investigations. None provides perfect information that would be right in all cases all the time. Which method of eliciting information provides more valid information regarding health of the person?
Laboratory and radiological investigations are generally believed more than others as they are objective and have least human element. However, validity of laboratory results, for example, depends on whether or not the apparatus, reagents and procedures used are fully standardized. Even then, as mentioned earlier, they do provide false negative and false positive results in some cases. Moreover, some clinicians believe that nothing outscores the feeling they get of the condition of the person by clinical examination. For them, investigations are just for support or confirmation, and do not have much value by themselves. This is because, first that the laboratory results can be in error, second because some people have so called abnormal levels even when they are completely healthy, and third because health is more of a perception of the affected individual than his/her organic state. The same is generally true for radiological investigations. In most cases, holistic picture obtained by the combination of clinical information and investigation results provide much more valid information about the condition of the patients.
Preceding discussion may have given you an idea of how difficult assessment of validity is. Each tool has multifarious aspects and its performance in providing correct information depends on a host of features. Consider, for example, forms for eliciting and recording the information, as commonly used in working up the patients in clinics and most research studies including surveys. A form could be a questionnaire, schedule or a proforma. See this topic for their relative merits and demerits. Validity of the information obtained by these tools depends on, among others, their contents. For example, burden of smoking is assessed generally by the duration and number of cigarettes smoked. Sometimes information on type of smoking (cigarette, cigar, pipe, water pipe, bidi, etc.) is also obtained. In some rare cases, the age at initiation and time elapsed since quitting by ex-smokers is also obtained as done for Global Adult Tobacco Surveys in different countries [3]. But how to validly combine all these aspects of smoking into a single index is a question addressed by Indrayan smoking index.
Validity of response also depends on interview technique, patient cooperation, biases and prejudices of both the interviewer and the interviewee, rapport between them, and the like. It also depends on the sequence of questions, length of the questions and of the questionnaire, their wording, etc., besides the statistical scale (metric, ordinal, nominal polytomous, or nominal dichotomous) used to elicit and record the response. For example, Likert scale is commonly used to elicit opinion or satisfaction with gradation from most adverse to most favorable. The response on this scale may differ if you use 0 to 6 scores than if you use –3 to +3 scores despite that both are 7-point scales. This illustrates how the concept of validity becomes intricate as we go deeper.
In the context of a questionnaire or a schedule, validity is assessed in terms of, for example, its ability to distinguish between a sick and a healthy subject or a very sick and a not-so-sick subject. This means that the scores received or the responses obtained from one group of subjects should be sufficiently different from those of another group when the two groups are known to be different with respect to the characteristic under assessment. Consider a questionnaire containing 20 items measuring quality of life. If the response on one particular item, say on physical independence, from the healthy subjects is nearly the same as from the mentally retarded subjects, this item is not valid for measuring quality of life in those types of subjects, and the item can be deleted. A shorter questionnaire is always better than a longer questionnaire—thus deletion always helps. But the number of items finally left should be adequate to assess all the domains of the construct under evaluation.
Validity of the Design, Variables under Study, and of Assumptions
Medical researchers commonly face the problem of validity of their design, variables to be studied and assumptions. When any of them lacks validity, the results will be affected.
A valid design is the one that would rightly answer the question the study is intended to answer. For example, a one-way design cannot provide right answer on effect of two nominal factors on a quantitative outcome. Kaestner [4] found that the pre- versus postintervention design with a control group for studying effect of state Medicaid expansion on mortality in low-income adults is invalid because prior trends in the treatment states and control states differed significantly. Case-control design, for that matter any observational study, is generally not valid for reaching at cause-effect relationship as this type of study provides associational results except when a set of other strict criteria is met.
Similarly, one has to choose right variables or factors for getting valid results from a study. For example, for studying correlates of an outcome such as duration of hospitalization, severity of condition at admission by itself may not be valid and you may have to consider other factors also such as age, treatment strategies, nursing care, and overall health of the person for responding to the treatment. Operational definitions of each of these variables should also be valid. For example, nursing care could be assessed in terms of responding to the specific needs of the patient throughout the stay, sticking to the prescribed regimen, proper entries in bedhead tickets, etc. If something is missing or not properly recorded, validity will suffer in the sense that right answers to the question of what and how much of duration of hospitalization is affected by different correlates will not be obtained. For statistical methods such as regression, choice of regressors ... ...
For final and full version, see
Concise Encyclopedia of Biostatistics for Medical Professionals
Concise Encyclopedia of Biostatistics for Medical Professionals)
validity, see also validity (types of)
Validity of a tool is its ability to assess correctly or its appropriateness for use in a particular setup. In medicine, the term is used for devices, factors, data, design, estimate, evidence, tests, results, scoring systems, studies, and a host of other tools. Do not confuse this with accuracy, Accuracy is generally for a single measurement whereas validity is the ability to hit the target on average.
There is some confusion in the literature about the terms validity and reliability. The difference between the two is aptly illustrated in Figure V.1. Reliability is hitting the same point in repeated attempts although this may be far away from the target (see third panel). Validity is hitting around the target (second panel). If hits are close together and near the target every time, both reliability and validity are high (fourth panel). Lack of validity can be due to systematic bias or for any other reason. See bias in medical studies and their minimization for further details of the types of bias that can affect validity. If the bias is small, we say that the tool has high validity and if the bias is large we say that the validity is low.
What signs and symptoms or hematological parameters (such as hematocrit) can correctly identify cases of dengue fever in early stages because serological evidence takes time? Is BP > 140/90 mmHg the right definition for hypertension or is BP > 160/95 more correct? Both the definitions are used. (See [1, 2], these incidentally are nearly consecutive articles in the same journal but with varying definitions.) This means that those with BP = 150/92 are considered hypertensive by one definition but not by the other. How can one distinguish, without error, a hypothyroid condition from euthyroid goiter? How can one correctly ascertain cause of death in an inaccessible rural area where a medical doctor is not available? How can age be correctly assessed when a dependable record is not available? Can the diet content of an individual be adequately assessed by taking a three-day history? How can physical activity be validly measured? Many other examples can be cited where validity is an important concern.
Validity is context-specific, for example, high validity of a tool in hospital-A does not necessarily mean that this will be so in hospital-B as well. A highly valid tool in better nourished children may not work well in under-nourished children. It intimately depends on the case mix. Thus validity is qualified for the type of subjects it is evaluated.
Validity of Diagnostic Tests
In practice, no medical test is 100% perfect. A computed tomography (CT) scan can give a false-negative or false-positive result, and a negative histologic result for a specimen is no guarantee that proliferation is absent although in this case positive predictivity is nearly 100%. The values of measurements such as creatinine level, platelet count, and total lung capacity are indicative of different medical conditions rather than absolute, i.e., they mostly estimate the likelihood of a disease. Signs and symptoms seldom provide infallible evidence, and have to be supplemented with other clinical information for coming to any conclusion worth implementing.
Because all these tools are imperfect, decisions based on them are also necessarily probabilistic rather than definitive. Their validity in a particular setup is generally measured in terms of indices such as sensitivity and specificity and positive and negative predictivities (see these topics for details). These terms are applied not just to the conventional laboratory and radiological tests but also to the other clinical evaluation tools such as signs and symptoms, and attitudes and behavior. These indices measure the validity of these tools on 0–1 scale with 0 saying not helpful at all and 1 saying they are perfect in reaching to a right conclusion. The details under those topics will tell you that sometimes highly sensitive and sometimes highly specific test is more valid for a particular application. Also, that sensitivity-specificity are evaluated on subjects who are already known to have or not have the disease or the condition, whereas predictivities provide valid measurement of the diagnostic utility of the tools in local context. You may also like to review the topic receiver operating characteristic (ROC) curves that provide information on overall performance of quantitative tests on the basis of sensitivity-specificity of the quantitative tests at different cutoffs.
Validity of Medical Information
Besides diagnostic tools, other ‘tools’ used in health and medicine include information on a patient or a person obtained in a variety of ways – previous records, interview, examination, and investigations. None provides perfect information that would be right in all cases all the time. Which method of eliciting information provides more valid information regarding health of the person?
Laboratory and radiological investigations are generally believed more than others as they are objective and have least human element. However, validity of laboratory results, for example, depends on whether or not the apparatus, reagents and procedures used are fully standardized. Even then, as mentioned earlier, they do provide false negative and false positive results in some cases. Moreover, some clinicians believe that nothing outscores the feeling they get of the condition of the person by clinical examination. For them, investigations are just for support or confirmation, and do not have much value by themselves. This is because, first that the laboratory results can be in error, second because some people have so called abnormal levels even when they are completely healthy, and third because health is more of a perception of the affected individual than his/her organic state. The same is generally true for radiological investigations. In most cases, holistic picture obtained by the combination of clinical information and investigation results provide much more valid information about the condition of the patients.
Preceding discussion may have given you an idea of how difficult assessment of validity is. Each tool has multifarious aspects and its performance in providing correct information depends on a host of features. Consider, for example, forms for eliciting and recording the information, as commonly used in working up the patients in clinics and most research studies including surveys. A form could be a questionnaire, schedule or a proforma. See this topic for their relative merits and demerits. Validity of the information obtained by these tools depends on, among others, their contents. For example, burden of smoking is assessed generally by the duration and number of cigarettes smoked. Sometimes information on type of smoking (cigarette, cigar, pipe, water pipe, bidi, etc.) is also obtained. In some rare cases, the age at initiation and time elapsed since quitting by ex-smokers is also obtained as done for Global Adult Tobacco Surveys in different countries [3]. But how to validly combine all these aspects of smoking into a single index is a question addressed by Indrayan smoking index.
Validity of response also depends on interview technique, patient cooperation, biases and prejudices of both the interviewer and the interviewee, rapport between them, and the like. It also depends on the sequence of questions, length of the questions and of the questionnaire, their wording, etc., besides the statistical scale (metric, ordinal, nominal polytomous, or nominal dichotomous) used to elicit and record the response. For example, Likert scale is commonly used to elicit opinion or satisfaction with gradation from most adverse to most favorable. The response on this scale may differ if you use 0 to 6 scores than if you use –3 to +3 scores despite that both are 7-point scales. This illustrates how the concept of validity becomes intricate as we go deeper.
In the context of a questionnaire or a schedule, validity is assessed in terms of, for example, its ability to distinguish between a sick and a healthy subject or a very sick and a not-so-sick subject. This means that the scores received or the responses obtained from one group of subjects should be sufficiently different from those of another group when the two groups are known to be different with respect to the characteristic under assessment. Consider a questionnaire containing 20 items measuring quality of life. If the response on one particular item, say on physical independence, from the healthy subjects is nearly the same as from the mentally retarded subjects, this item is not valid for measuring quality of life in those types of subjects, and the item can be deleted. A shorter questionnaire is always better than a longer questionnaire—thus deletion always helps. But the number of items finally left should be adequate to assess all the domains of the construct under evaluation.
Validity of the Design, Variables under Study, and of Assumptions
Medical researchers commonly face the problem of validity of their design, variables to be studied and assumptions. When any of them lacks validity, the results will be affected.
A valid design is the one that would rightly answer the question the study is intended to answer. For example, a one-way design cannot provide right answer on effect of two nominal factors on a quantitative outcome. Kaestner [4] found that the pre- versus postintervention design with a control group for studying effect of state Medicaid expansion on mortality in low-income adults is invalid because prior trends in the treatment states and control states differed significantly. Case-control design, for that matter any observational study, is generally not valid for reaching at cause-effect relationship as this type of study provides associational results except when a set of other strict criteria is met.
Similarly, one has to choose right variables or factors for getting valid results from a study. For example, for studying correlates of an outcome such as duration of hospitalization, severity of condition at admission by itself may not be valid and you may have to consider other factors also such as age, treatment strategies, nursing care, and overall health of the person for responding to the treatment. Operational definitions of each of these variables should also be valid. For example, nursing care could be assessed in terms of responding to the specific needs of the patient throughout the stay, sticking to the prescribed regimen, proper entries in bedhead tickets, etc. If something is missing or not properly recorded, validity will suffer in the sense that right answers to the question of what and how much of duration of hospitalization is affected by different correlates will not be obtained. For statistical methods such as regression, choice of regressors ... ...
For final and full version, see
Concise Encyclopedia of Biostatistics for Medical Professionals
